Unlocking Zero-Resource Machine Translation to Support New Languages in Google Translate
Machine translation (MT) technology has made significant advances in recent years, as deep learning has been integrated with natural language processing (NLP). Performance on research benchmarks like WMT have soared, and translation services have improved in quality and expanded to include new languages. Nevertheless, while existing translation services cover languages spoken by the majority of people world wide, they only include around 100 languages in total, just over 1% of those actively spoken globally. Moreover, the languages that are currently represented are overwhelmingly European, largely overlooking regions of high linguistic diversity, like Africa and the Americas.
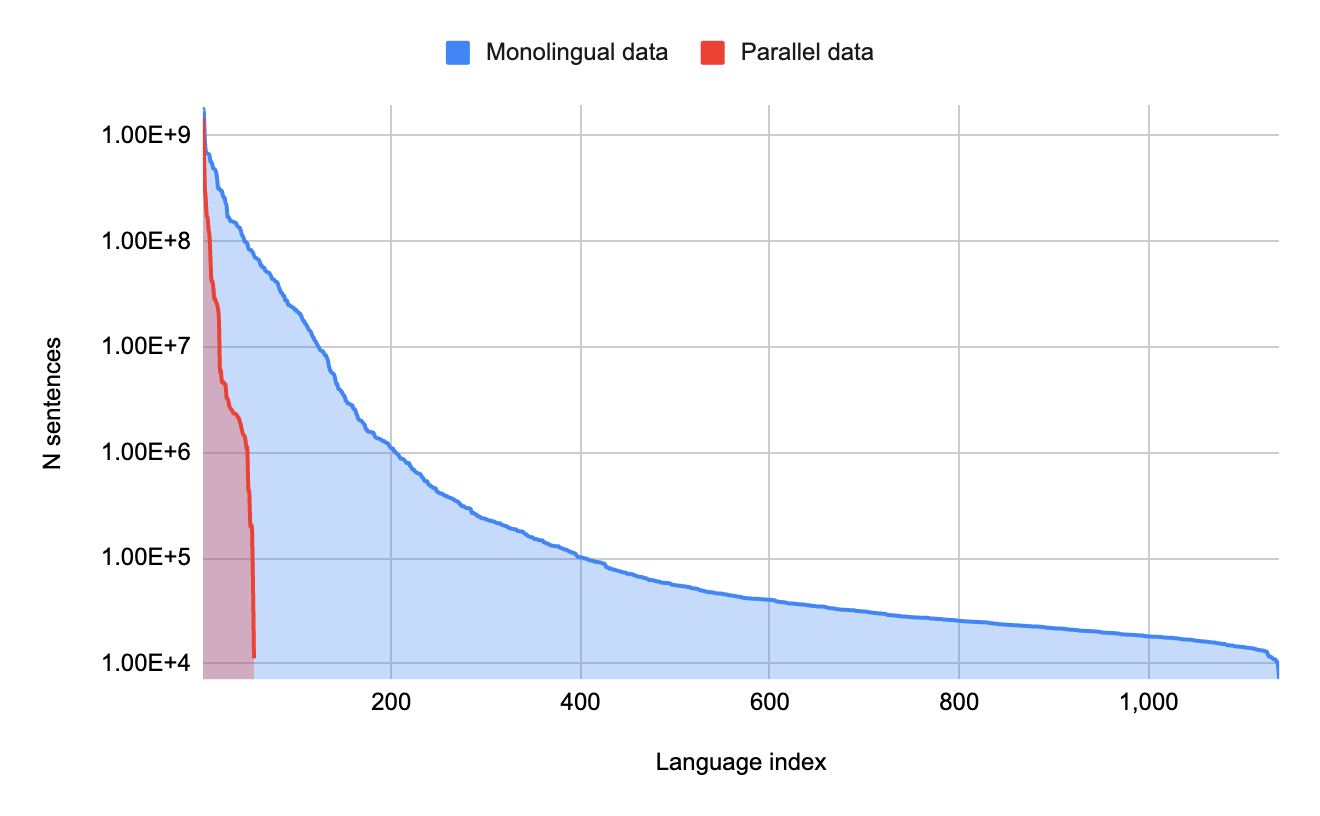
There are two key bottlenecks towards building functioning translation models for the long tail of languages. The first arises from data scarcity; digitized data for many languages is limited and can be difficult to find on the web due to quality issues with Language Identification (LangID) models. The second challenge arises from modeling limitations. MT models usually train on large amounts of parallel (translated) text, but without such data, models must learn to translate from limited amounts of monolingual text, which is a novel area of research. Both of these challenges need to be addressed for translation models to reach sufficient quality.
In “Building Machine Translation Systems for the Next Thousand Languages”, we describe how to build high-quality monolingual datasets for over a thousand languages that do not have translation datasets available and demonstrate how one can use monolingual data alone to train MT models. As part of this effort, we are expanding Google Translate to include 24 under-resourced languages. For these languages, we created monolingual datasets by developing and using specialized neural language identification models combined with novel filtering approaches. The techniques we introduce supplement massively multilingual models with a self supervised task to enable zero-resource translation. Finally, we highlight how native speakers have helped us realize this accomplishment.
New languages added to Google Translate:

The amount of monolingual data per language versus the amount of parallel (translated) data per language:
Paper: Building Machine Translation Systems for the Next Thousand Languages
