Seemingly, epub files are making use of HTML which gives you the ability to automatically parse a book, translate the words, and then generate an interlinear ebook. One example of this is interlinearizer that makes use of Calibre's ebook-convert to convert it into htmlz and then the googletrans library to translate the words.
Unfortunately the googletrans library is making use of a technique that Google has tried to shut down so a lot of people are having issues with it. I played around with deep-translator myself as a replacement but found similar issues. Another option would be to pay for an API but I reckon it could quickly get expensive to translate full ebooks.
I'm aware that there are quite a few translation projects published on this forum. I'm curious if anyone have tried to generate interlinear ebooks or maybe if you have any translation libraries to recommend.
Generating interlinear ebooks for e-readers
-
Stefan
- Green Belt
- Posts: 379
- Joined: Sun Dec 20, 2015 9:59 pm
- Location: Sweden
- Languages: -
- x 920
- Contact:
-
rdearman

- Site Admin
- Posts: 7260
- Joined: Thu May 14, 2015 4:18 pm
- Location: United Kingdom
- Languages: English (N)
- Language Log: viewtopic.php?f=15&t=1836
- x 23317
- Contact:
Re: Generating interlinear ebooks for e-readers
There is someone on the forum who does this. But what you could do is extract all the unique words. Put them into a CSV and upload into Google sheets, use the =Googletranslate() function then use the translated words for the interlined book.
There is no limit on the Google sheets lookups.
There is no limit on the Google sheets lookups.
6 x
: Read 150 books in 2024
My YouTube Channel
The Autodidactic Podcast
My Author's Newsletter
I post on this forum with mobile devices, so excuse short msgs and typos.
My YouTube Channel
The Autodidactic Podcast
My Author's Newsletter
I post on this forum with mobile devices, so excuse short msgs and typos.
-
Stefan
- Green Belt
- Posts: 379
- Joined: Sun Dec 20, 2015 9:59 pm
- Location: Sweden
- Languages: -
- x 920
- Contact:
Re: Generating interlinear ebooks for e-readers
Thank you for the recommendation. Google Spreadsheets by far exceeded my expectations.
I played around with it and found a method that should be able to generate an interlinear ebook out of any epub. Here's an example of Harry Potter und der Feuerkelch since I had it available. Naturally it isn't perfect since it's missing context. weiß means white but also know. glaube would be more appropriately translated as believe in this context and not faith. But that's to be expected from word-by-word translations. I still reckon it's highly usable to figure out context when reading.

This might seem like a lot of steps but there's only about 5 minutes of actual work involved. Note that I'm using French (fr) to English (en) in the example and that I renamed my book to a.epub before starting since I'm lazy and don't want to type the full book name into the terminal. Also note that this method is centered around Linux since I couldn't get Interlinearizer to work with Windows. The easiest way to get around this is to run Linux in a virtual machine such as VirtualBox on Windows.
Preparations
Install Python.
Download Interlinearizer, place it in a permanent folder and install the requirements.
At the bottom of the file interlinearize.py, comment out the call to construct_word_list_from_text(), by adding # in front of it. The purpose of this function is to build your own dictionary by looking up the words through Google Translate, but since no library works we'll instead build our own dictionary through Google Spreadsheet. The proper method would be to pay for an API and rewrite this function to make use of it.
Install Calibre.
Install Sublime Text or a similar text editor.
Place the epub ebook in your Interlinearizer folder and open the terminal.
Run the following command to convert the book (a.epub) into pure text (a.txt) with Calibre:
Then convert the text file (a.txt) into a sorted unique wordlist. This could be improved with regex:
Open the new file in Sublime (or other text editor) with utf-8 chosen as character encoding and remove lines with charset errors such as \. Manually picking the correct character encoding is important since the errors will confuse the text editor and cause it to not being able to interpret utf-8 characters. Personally I first do a search after \ to see the types of errors such as \94 and then I do a search and replace, replacing it with nothing. This might cause a few duplicate lines since \94you and you were both included and now both lines will say you. To me this isn't an issue, but you could filter out duplicates again if you want to.
Copy the wordlist from Sublime and paste into Google Spreadsheet in cell A1 and it will automatically fill the whole A column.
In B1, add the translation formula:
Select the B1 cell, double click on the blue rectangle in the bottom right corner of the cell. It will now automatically fill the whole column and translate all the rows.
Wait for it to translate thousands of words. The 17 000 unique words in this Harry Potter book took roughly 20 minutes but it handles everything automatically so just leave it in the background while you do something fun. Other languages might have fewer words if they are not as compound heavy as German is. I'm looking at you vierhundertundzweiundzwanzigsten and allzweck-magische-sauerei-entferner...
Once completed, download the sheet as a tab delimited file (.tsv).
Rename the file appropriately based on your language such as "fr_en.txt" and then place it in the "dicts" folder in Interlinearizer. Note that it's _ and not -. This file is your new language specific dictionary and in theory you could expand upon it and continue to translate other books without having to go through any of the steps above.
Run the following command to create the interlinear book based on your original book and the dictionary:
You should now have a perfect bilingual book.
A note on Kindle

By habit, I share ebooks to my Kindle by importing them to Calibre and then sending them to my device by the built-in email. When doing this, Calibre converts the ebook to the mobi format and it seemingly does a poor job of interpreting interlinear texts. See the left hand example in the image. Instead, you have to use the azw3 format and transfer them manually (since Kindle doesn't support epub). As a result, you can use this command to generate the interlinear ebook directly in the azw3 format instead of having to go through epub:
The result is the image above in the middle which looks quite alright. However, when you adjust the font-size on your Kindle, it starts to break down due to the css formatting in Interlinearizer, as visible in the far right image. Fortunately you can easily modify this in interlinear.css and I made it responsive to adjust for both font-size and spacing. My solution isn't perfect though since the translation at the bottom of the page sometimes falls over to the next page.
I played around with it and found a method that should be able to generate an interlinear ebook out of any epub. Here's an example of Harry Potter und der Feuerkelch since I had it available. Naturally it isn't perfect since it's missing context. weiß means white but also know. glaube would be more appropriately translated as believe in this context and not faith. But that's to be expected from word-by-word translations. I still reckon it's highly usable to figure out context when reading.
This might seem like a lot of steps but there's only about 5 minutes of actual work involved. Note that I'm using French (fr) to English (en) in the example and that I renamed my book to a.epub before starting since I'm lazy and don't want to type the full book name into the terminal. Also note that this method is centered around Linux since I couldn't get Interlinearizer to work with Windows. The easiest way to get around this is to run Linux in a virtual machine such as VirtualBox on Windows.
Preparations
Install Python.
Download Interlinearizer, place it in a permanent folder and install the requirements.
At the bottom of the file interlinearize.py, comment out the call to construct_word_list_from_text(), by adding # in front of it. The purpose of this function is to build your own dictionary by looking up the words through Google Translate, but since no library works we'll instead build our own dictionary through Google Spreadsheet. The proper method would be to pay for an API and rewrite this function to make use of it.
Install Calibre.
Install Sublime Text or a similar text editor.
Place the epub ebook in your Interlinearizer folder and open the terminal.
Run the following command to convert the book (a.epub) into pure text (a.txt) with Calibre:
Code: Select all
ebook-convert a.epub a.txtThen convert the text file (a.txt) into a sorted unique wordlist. This could be improved with regex:
Code: Select all
cat a.txt | tr '[:upper:]' '[:lower:]' | tr '"!#$%&()*+,./:;<=>?@[\]^_{|}~«»‘’”“–' ' ' | tr ' ' '\n' | sort | uniq > b.txtOpen the new file in Sublime (or other text editor) with utf-8 chosen as character encoding and remove lines with charset errors such as \. Manually picking the correct character encoding is important since the errors will confuse the text editor and cause it to not being able to interpret utf-8 characters. Personally I first do a search after \ to see the types of errors such as \94 and then I do a search and replace, replacing it with nothing. This might cause a few duplicate lines since \94you and you were both included and now both lines will say you. To me this isn't an issue, but you could filter out duplicates again if you want to.
Copy the wordlist from Sublime and paste into Google Spreadsheet in cell A1 and it will automatically fill the whole A column.
In B1, add the translation formula:
Code: Select all
=GOOGLETRANSLATE(A1; "fr"; "en")Select the B1 cell, double click on the blue rectangle in the bottom right corner of the cell. It will now automatically fill the whole column and translate all the rows.
Wait for it to translate thousands of words. The 17 000 unique words in this Harry Potter book took roughly 20 minutes but it handles everything automatically so just leave it in the background while you do something fun. Other languages might have fewer words if they are not as compound heavy as German is. I'm looking at you vierhundertundzweiundzwanzigsten and allzweck-magische-sauerei-entferner...
Once completed, download the sheet as a tab delimited file (.tsv).
Rename the file appropriately based on your language such as "fr_en.txt" and then place it in the "dicts" folder in Interlinearizer. Note that it's _ and not -. This file is your new language specific dictionary and in theory you could expand upon it and continue to translate other books without having to go through any of the steps above.
Run the following command to create the interlinear book based on your original book and the dictionary:
Code: Select all
python3 interlinearize.py fr en "a.epub" "a (interlinearized).epub"You should now have a perfect bilingual book.
A note on Kindle
By habit, I share ebooks to my Kindle by importing them to Calibre and then sending them to my device by the built-in email. When doing this, Calibre converts the ebook to the mobi format and it seemingly does a poor job of interpreting interlinear texts. See the left hand example in the image. Instead, you have to use the azw3 format and transfer them manually (since Kindle doesn't support epub). As a result, you can use this command to generate the interlinear ebook directly in the azw3 format instead of having to go through epub:
Code: Select all
python3 interlinearize.py fr en "a.epub" "a (interlinearized).azw3"The result is the image above in the middle which looks quite alright. However, when you adjust the font-size on your Kindle, it starts to break down due to the css formatting in Interlinearizer, as visible in the far right image. Fortunately you can easily modify this in interlinear.css and I made it responsive to adjust for both font-size and spacing. My solution isn't perfect though since the translation at the bottom of the page sometimes falls over to the next page.
Code: Select all
.il_paragraph {
width: 100%;
overflow-wrap: anywhere;
}
.il_word {
position: relative;
display: inline-block;
padding: 0 .2em;
text-align: center;
margin: .5em 0;
overflow-wrap: normal;
}
.il_word:first-child {
padding-left: 0;
}
.il_word:last-child {
padding-right: 0;
}
.il_translation {
width: 100%;
top: .2em;
text-align: center;
color: #888;
position: relative;
-webkit-user-select: none;
-moz-user-select: none;
-ms-user-select: none;
user-select: none;
}
.not-word, .missing-translation {
padding-left: 0;
padding-right: 0;
}
7 x
-
Keys

- Yellow Belt
- Posts: 92
- Joined: Sat Oct 24, 2015 1:54 am
- Location: Toronto
- Languages: Dutch (N), English (C2), German (C1), French (B2), Swedish (B2), Spanish (B2), Italian (B2), Russian (B2), Hungarian (B1), Polish (B1), Urdu (A2); reading literature and listening to audiobooks in Danish, Dutch, English, French, German, Hungarian, Indonesian, Italian, Polish, Portuguese, Russian, Swedish and Spanish. Studying Urdu, Polish atm.
- x 264
- Contact:
Re: Generating interlinear ebooks for e-readers
For the HypLern project we have a tool for creating interlinear books as well.
If you make a user on https://hyplern.com we can set it to the translator role if you pm us.
With permission from Crush who made this tool:
Books dashboard, go to languages (dashboard will give error first time as there are no books)
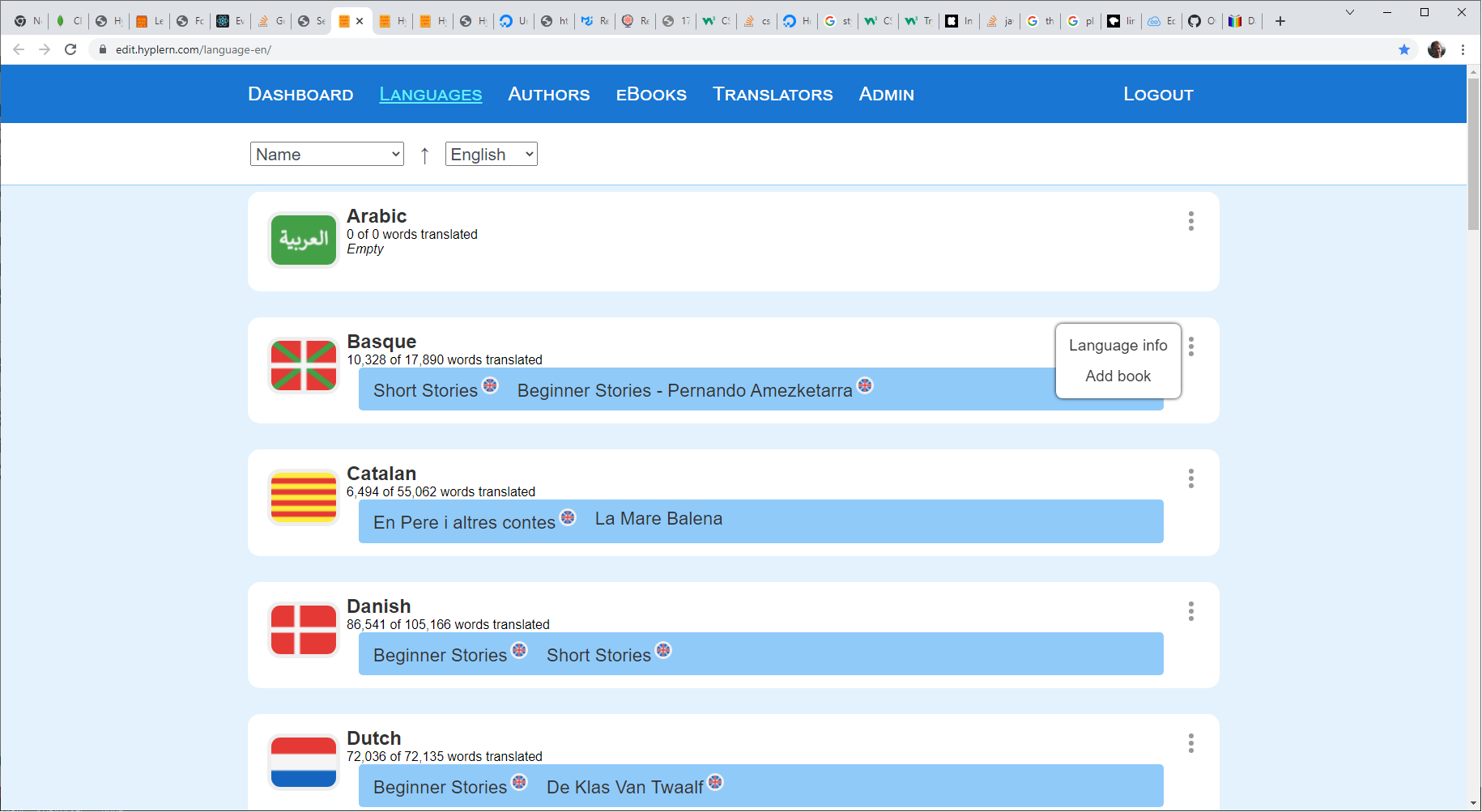
Click three dot menu to the right of a language and "Add book"
"Add sub section" for each chapter and fill out the chapter title, and original title and author as well. It's possible to add a book with parts with each having their own chapters as well, but I think pdf / epub creation for that isn't fully up yet.

Once it's in that language directory you now see the book, add an English translation for example and start translating
You can press "pretranslate". Here we have the same issue with Google translation mentioned in the other post above, it used to 100% pre-translate using google, automatically, but now it doesn't translate all the words.
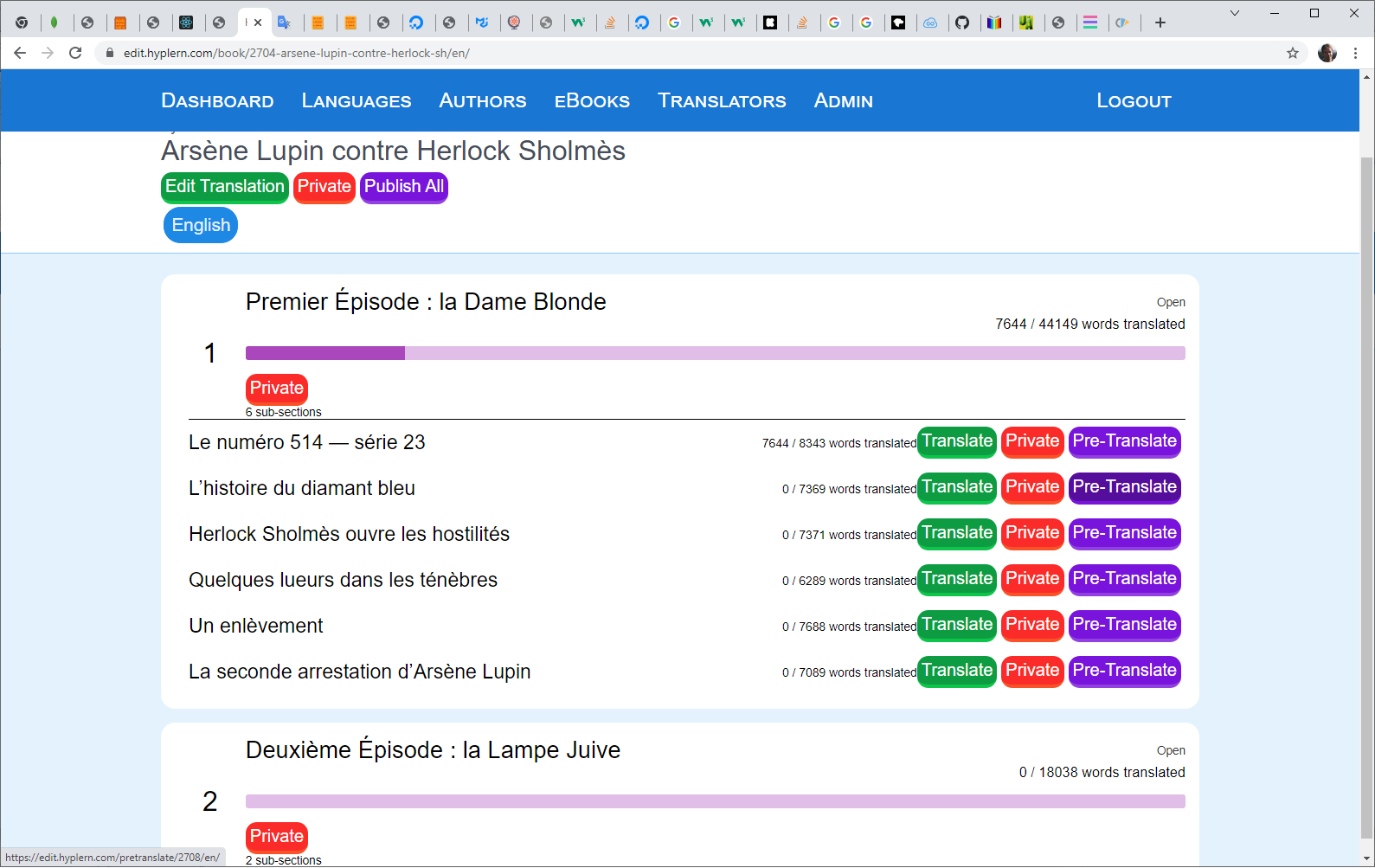
However the more words we have in a language already translated, the more are pretranslated so you can ride along on our work there.
So for French for example there's only a few words you'd have to translate, apart from the words you need to correct. The second line is optional btw, it's handy to explain in idiom if the literal translation is too unclear.
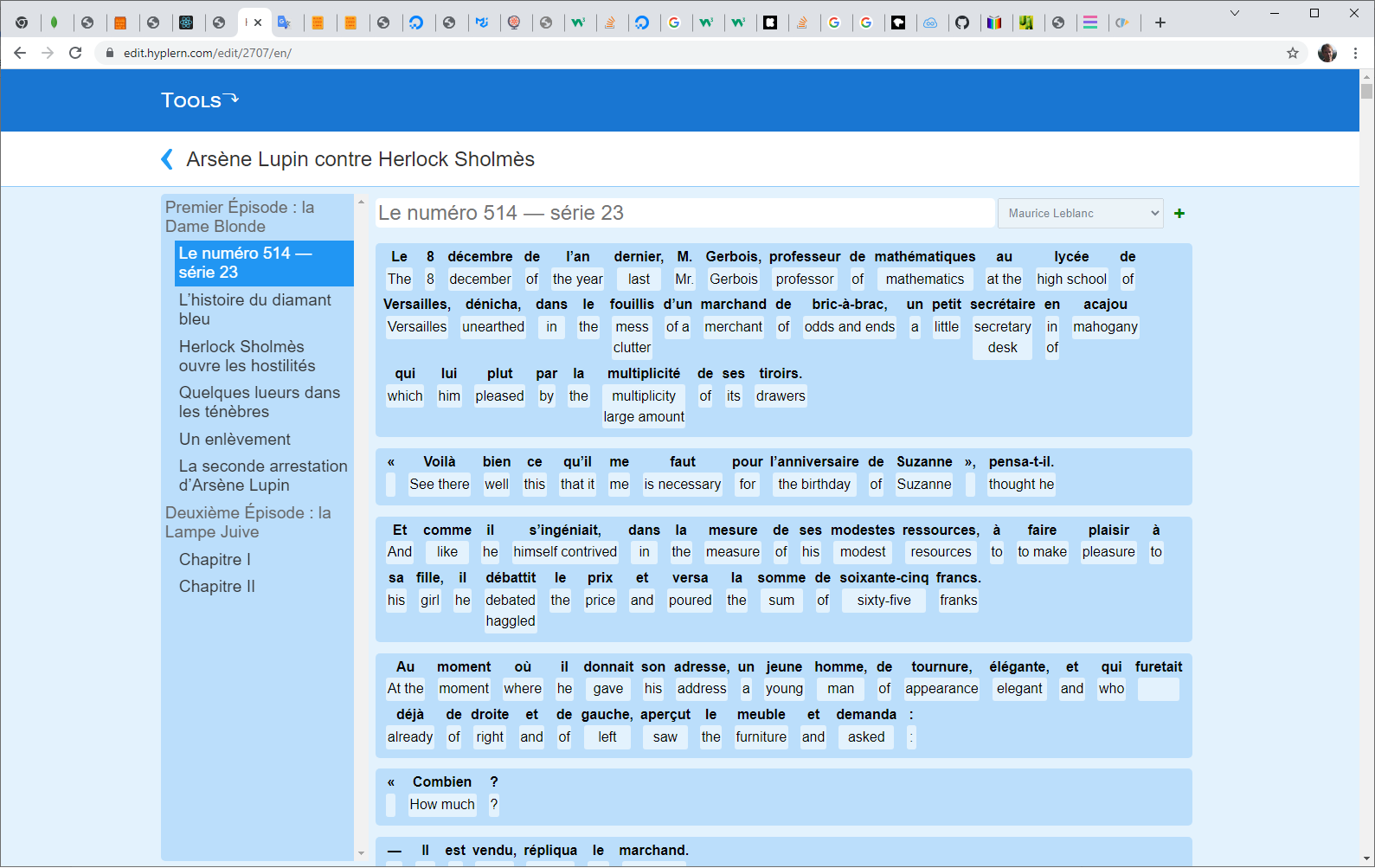
When you have translated a book, there's an option to create an ebook (pdf or epub) from it, with or without cover, etc. They can also be visible on hyplern.com once someone has peer reviewed it
Here's an example of a Chinese epub:
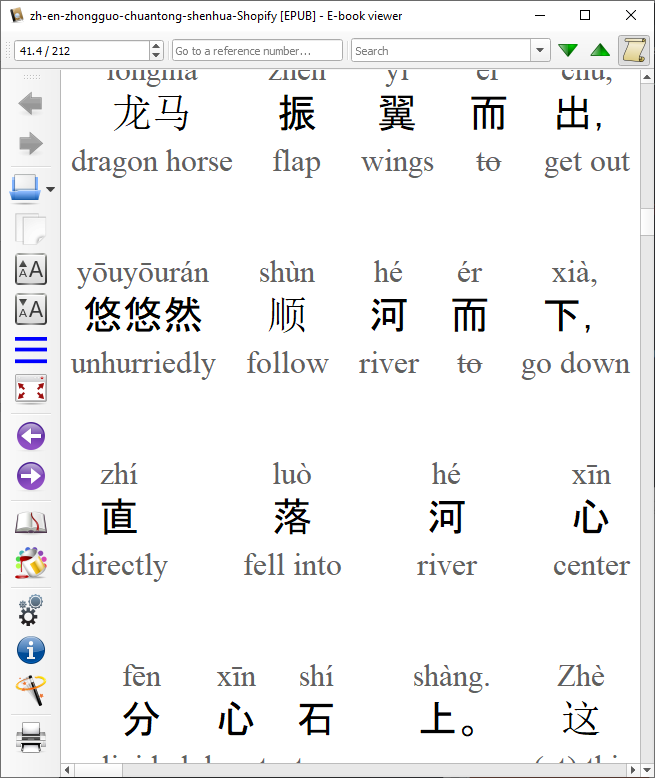
At this point it's probably handy to do smaller books as our project is meant for manually corrected books and not sure if anyone is going to go through whole Harry Potters.
Also only PD (public domain) books but there will be an open source version that you can download and do anything you like with, I think, in the future.
If you make a user on https://hyplern.com we can set it to the translator role if you pm us.
With permission from Crush who made this tool:
Books dashboard, go to languages (dashboard will give error first time as there are no books)
Click three dot menu to the right of a language and "Add book"
"Add sub section" for each chapter and fill out the chapter title, and original title and author as well. It's possible to add a book with parts with each having their own chapters as well, but I think pdf / epub creation for that isn't fully up yet.
Once it's in that language directory you now see the book, add an English translation for example and start translating
You can press "pretranslate". Here we have the same issue with Google translation mentioned in the other post above, it used to 100% pre-translate using google, automatically, but now it doesn't translate all the words.
However the more words we have in a language already translated, the more are pretranslated so you can ride along on our work there.
So for French for example there's only a few words you'd have to translate, apart from the words you need to correct. The second line is optional btw, it's handy to explain in idiom if the literal translation is too unclear.
When you have translated a book, there's an option to create an ebook (pdf or epub) from it, with or without cover, etc. They can also be visible on hyplern.com once someone has peer reviewed it
Here's an example of a Chinese epub:
At this point it's probably handy to do smaller books as our project is meant for manually corrected books and not sure if anyone is going to go through whole Harry Potters.
Also only PD (public domain) books but there will be an open source version that you can download and do anything you like with, I think, in the future.
5 x
-
Cecilita17
- Posts: 2
- Joined: Thu Mar 07, 2024 9:41 pm
- Languages: Spanish (N) English (C1) Polish (A2) German (B1) Russian (B1)
- x 4
Re: Generating interlinear ebooks for e-readers
Hi! I know your post is old, but I used your method and it works, thank you!
I was wondering if you know how to use this method for languages that use special characters or different alphabets. I've encountered an error while creating a polish English dictionary because visual studio code and Sublime don't recognize the letters ę and ą in polish and they replace them with a modified form of "?" So I'm left with 1000 words that can't be translated.
I'd be grateful if you can help me!
I was wondering if you know how to use this method for languages that use special characters or different alphabets. I've encountered an error while creating a polish English dictionary because visual studio code and Sublime don't recognize the letters ę and ą in polish and they replace them with a modified form of "?" So I'm left with 1000 words that can't be translated.
I'd be grateful if you can help me!
1 x
-
Doitsujin
- Green Belt
- Posts: 404
- Joined: Sat Jul 18, 2015 6:21 pm
- Languages: German (N)
- x 807
Re: Generating interlinear ebooks for e-readers
This usually happens because of encoding problems. Try the following:Cecilita17 wrote:I was wondering if you know how to use this method for languages that use special characters or different alphabets. I've encountered an error while creating a polish English dictionary because visual studio code and Sublime don't recognize the letters ę and ą in polish and they replace them with a modified form of "?"
- Download and install Notepad++
- Open the source file with it.
- Check the encoding shown in the bottom right corner.
- If it doesn't say UTF-8, press CTRL+A followed by CTRL+C.
- Create a blank UTF-8 file, press CTRL+V and save it.
6 x
-
Dragon27
- Blue Belt
- Posts: 620
- Joined: Tue Aug 25, 2015 6:40 am
- Languages: Russian (N)
English - best foreign language
Polish, Spanish - passive advanced
Tatar, German, French, Greek - studying - x 1386
Re: Generating interlinear ebooks for e-readers
Doitsujin wrote:
- Download and install Notepad++
- Open the source file with it.
- Check the encoding shown in the bottom right corner.
- If it doesn't say UTF-8, press CTRL+A followed by CTRL+C.
- Create a blank UTF-8 file, press CTRL+V and save it.
Thank you! I had so much trouble getting any of the book readers I had to read Japanese books from txt files, because reading them just in a text editor or a browser (which, apparently, has no problem recognizing the encoding) is so inconvenient.
1 x
-
Cecilita17
- Posts: 2
- Joined: Thu Mar 07, 2024 9:41 pm
- Languages: Spanish (N) English (C1) Polish (A2) German (B1) Russian (B1)
- x 4
Re: Generating interlinear ebooks for e-readers
I tried but it doesn't seem to solve my issue :/
I found a different solution, I have only tested it with polish so far so I don't know about other languages.
I have modified the way to create the dictionary. This is how i do it:
ebook-convert a.epub a.txt
cat a.txt | tr -s '[:space:]' '\n' > b.txt
cat b.txt | tr -s '[:space:]' '\n' | tr '[:upper:]' '[:lower:]' | grep -Eo '[[:alnum:]]+' | sort | uniq > c.txt
Also, the koreader ebook reader app is wonderful, if you generate the file in epub, it allows you to adjust the font and other stuff without having to modify the css of the interlinearizer. I found out after a lot of testing to increase font size to make pdf readable in mobile devices, it didn't work, but the koreader fixes it.
https://github.com/koreader/koreader/releases
I hope it'll be useful for someone else!
I found a different solution, I have only tested it with polish so far so I don't know about other languages.
I have modified the way to create the dictionary. This is how i do it:
ebook-convert a.epub a.txt
cat a.txt | tr -s '[:space:]' '\n' > b.txt
cat b.txt | tr -s '[:space:]' '\n' | tr '[:upper:]' '[:lower:]' | grep -Eo '[[:alnum:]]+' | sort | uniq > c.txt
Also, the koreader ebook reader app is wonderful, if you generate the file in epub, it allows you to adjust the font and other stuff without having to modify the css of the interlinearizer. I found out after a lot of testing to increase font size to make pdf readable in mobile devices, it didn't work, but the koreader fixes it.
https://github.com/koreader/koreader/releases
I hope it'll be useful for someone else!
3 x
Return to “General Language Discussion”
Who is online
Users browsing this forum: Asfaloth, GawainStan and 2 guests