
Software localization is the process of translating the human-visible text in a software program. (It also includes fixing number and date formats, and other things along those lines.)
As you might guess, the problem is that languages are tricky. In this older article by the linguists Sean M. Burke and Jordan Lachler, they show all the headaches involved in translating the following bits of text:
I scanned 12 directories.
Your query matched 10 files in 4 directories.
I thought it was a pretty amusing essay:
Then your Russian translator calls on the phone, to personally tell you the bad news about how really unpleasant your life is about to become:
...
He elaborates: In "I scanned %g directories", you'd expect "directories" to be in the accusative case (since it is the direct object in the sentence) and the plural number, except where $directory_count is 1, then you'd expect the singular, of course. Just like Latin or German. But! Where $directory_count % 10 is 1 ("%" for modulo, remember), assuming $directory count is an integer, and except where $directory_count % 100 is 11, "directories" is forced to become grammatically singular, which means it gets the ending for the accusative singular... You begin to visualize the code it'd take to test for the problem so far, and still work for Chinese and Arabic and Italian, and how many gettext items that'd take, but he keeps going... But where $directory_count % 10 is 2, 3, or 4 (except where $directory_count % 100 is 12, 13, or 14), the word for "directories" is forced to be genitive singular -- which means another ending... The room begins to spin around you, slowly at first... But with all other integer values, since "directory" is an inanimate noun, when preceded by a number and in the nominative or accusative cases (as it is here, just your luck!), it does stay plural, but it is forced into the genitive case -- yet another ending... And you never hear him get to the part about how you're going to run into similar (but maybe subtly different) problems with other Slavic languages like Polish, because the floor comes up to meet you, and you fade into unconsciousness.
(Thank you to zoul who linked to this article on another site.)
Mozilla has just released a specification for a new translation format that tries to address these issues. An example:
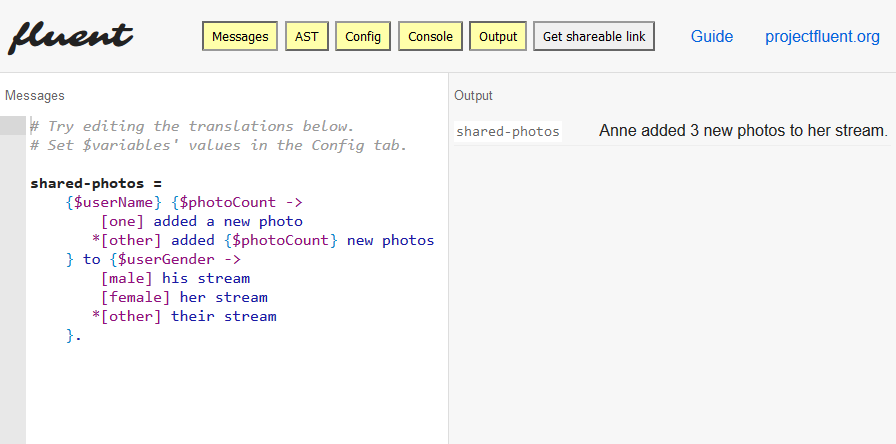
This is designed to support grammatically correct translations for a wide range of languages, including languages with really unusual grammatical constraints. And it's designed to work even when the original software authors don't understand Russian grammar.


